[현장 후기] Microsoft AI Tour 2025 – 하루 종일 AI에 푹 잠기다

오늘 하루는 말 그대로 AI의 축제였다.
양재 AT 센터에서 열린 Microsoft AI Tour
아침 9시부터 저녁 6시까지, 총 7개의 세션을 들으며 진짜 물리적으로도 정신적으로도 AI에 몰입한 하루였고,
예상보다 많은 관심으로 모인 참여자, 오랜만에 뵙는 지인 및 협력업체 분들... 그리고 직접 AI 에이전트 만들기까지...
중간중간 스피커의 한 마디 한 마디가 “곧 다가올 변화”를 예고하는 것처럼 다가왔다.
사티아 나델라
이번 행사의 하이라이트는 단연 Microsoft CEO 사티아 나델라의 키노트였다.
포멀한 키노트라기보단, 미래를 담담하게 그리는 짧은 TED 스타일 토크에 가까웠다.
그는 다음과 같은 메시지를 전했다:
“생성형 AI는 새로운 플랫폼 전환의 시작이다. 우리가 데이터를 어떻게 다루느냐가 기업의 미래를 결정할 것이다.”
현장의 공기는 꽤 진중했다. 쇼적인 요소보다는 실제 기업의 ‘전환’을 말하고 있었고,
이건 단순히 흥미로운 기술이 아니라 앞으로 누가 얼마나 빠르게 적응하느냐의 싸움이라는 걸 체감하게 했다.


그리고 수많은 세션이 있었지만, 선별적으로 내게 그리고 회사에 꼭 필요한 세션을 미리 정해서 참여했다.
| 시간 | 세션 |
| 9:15~10:00 | 금융산업 생성형 AI 비지니스 적용 기회 및 사례 |
| 10:00~10:15 | 소규모 게임 개발자의 글로벌 서비스를 위한 Azure AI 활용기 |
| 10:30~11:15 | AI 혁신, 데이터가 핵심이다! 분석 환경 구축 가이드 |
| 13:30~14:45 | Azure AI Foundry에서 모델과 에이전트 직접 다뤄보기 |
| 15:05~16:20 | Azure AI Agent Service로 나만의 AI 에이전트 만들기 |
| 16:55~17:40 | AI 전환을 위한 숨은 핵심. 클라우드 인프라 최적화 방안 |
이 중에서 오늘은 특히 많은 인사이트를 줬던 세션,
“AI 혁신, 데이터가 핵심이다!”
이 세션을 중심으로 내용을 간단히 요약해보려고 한다.
(※ 세션 기록과 사진 기반으로 정리한 내용이라, 직접 현장에서 들은 느낌 그대로 남기려 노력했다.)
Microsoft AI Tour 요약: AI 혁신, 데이터가 핵심이다!
세션명: AI 혁신, 데이터가 핵심이다! 분석 환경 구축 가이드
일시/장소: 2025년 3월 26일, 양재 AT 센터
발표자: Yabet Choi | Microsoft
세션 코드: BRK360-KR
"AI 혁신, 데이터가 핵심이다" 세션 요약 - 냉정하게 본 Microsoft Fabric
2025년 3월 26일, Microsoft AI Tour 현장 세션 중 가장 흥미로웠던 건 “AI 혁신, 데이터가 핵심이다”라는 워크숍. 단순한 AI 기술 소개가 아니라, AI를 제대로 돌리려면 데이터부터 정비해야 한다는 메시지가 핵심이었다.

“생성형 AI 솔루션을 만들기 위해선 멋진 모델만으론 부족하다. 결국 데이터가 정제되고, 통합되어 있어야 한다.”
→ 이 슬라이드는 발표자가 말하고자 한 오늘의 핵심 포인트를 요약한 장면
강력한 AI 모델과 Clean하고 통합된 데이터, 이 두 가지가 같이 갖춰져야 진짜 비즈니스 AI가 작동한다는 메시지를 던진다.

AI 혁신의 흐름을 4단계로 정리한 슬라이드.
데이터 통합 → AI에 사용할 수 있는 형태로 가공 및 연결 → AI 모델 훈련 → 인터랙티브 앱 및 개인화된 AI 솔루션 구축
결국 모델 훈련은 3단계일 뿐, 그 앞단계인 데이터 통합과 연결이 훨씬 더 핵심이라는 메시지를 전달 받았다.

많은 조직이 겪고 있는 현실적인 데이터 문제를 보여주는 장면.
비즈니스 팀과 기술 팀 간 데이터가 단절되고, 각자 중복 관리하면서 발생하는 문제는
① 비효율적 복제,
② 낮은 상호 활용성,
③ 보안 위험까지 초래한다는 지적.
AI 이전에 먼저 ‘데이터 환경’부터 정리돼야 한다는 강한 경고 메시지

발표자가 제시한 이상적인 데이터 환경의 청사진이라고 생각한다.
‘Open & Governed’라는 두 축을 중심으로, 다양한 데이터 소스를 통합한 데이터 레이크하우스 위에
AI 모델, 분석, 실시간 처리까지 유기적으로 연결된 구조, 클라우드 공급자와 데이터베이스가 뒤섞여 있어도 하나처럼 다룰 수 있어야 한다.

Microsoft의 지능형 데이터 플랫폼 구성도, Azure 기반 데이터베이스부터 분석, AI, 거버넌스까지 전 영역을 포괄하고 있으며, Fabric, Databricks, Purview 같은 핵심 도구들이 함께 제시됨
흥미로운 건 Oracle, Redis, Snowflake 등 타사 솔루션도 함께 보여주며 개방성을 강조한 점이다.

기존의 단절된 데이터 환경(Disconnected, 분리된 앱, 분석 도구 난립)을 하나의 통합된 플랫폼(Unified Stack)으로 바꾸는 게 Microsoft Fabric의 본질이고, 특히 "Built-in AI"라는 키워드를 통해, 분석만이 아니라 AI를 내장한 데이터 플랫폼이라는 정체성을 강조했다.

Microsoft Fabric은 단일 플랫폼이 아니라, 데이터 수집 → 분석 → 시각화 → 거버넌스까지 모두 아우르는 통합 생태계이다.
Copilot은 생성형 AI 기능, OneLake는 단일 데이터 저장소, Purview는 보안 및 거버넌스를 맡는다.
“이 모든 걸 하나에서 다 할 수 있다”는 메시지를 시각적으로 전달하는 장표

실제 Fabric 환경에서 데이터를 어떻게 복사하고 가져올 수 있는지를 보여주는 데모 장면

Microsoft Fabric은 단순한 데이터 플랫폼이 아니라,
AI 기능 내장형 SaaS 플랫폼,
멀티 클라우드 대응이 가능한 오픈형 데이터 레이크,
비즈니스 사용자를 위한 직관적 인사이트 제공 기능,
그리고 보안과 거버넌스를 내장한 미션 크리티컬한 플랫폼을 통합해
AI 시대에 필요한 전방위적 데이터 생태계를 구축하려는 비전을 담고 있다.
핵심은 엔지니어뿐만이 아니라 현업 사용자까지 고려한 통합형 아키텍처라는 점이다.


이 장면은 Microsoft Fabric에서의 Data Pipeline(데이터 흐름 시각화) 화면인데,
구조적으로는 Apache NiFi나 Azure Data Factory와 유사한 형태였다.
각 작업의 Git 상태, 소유자, 유입 데이터 상태 등을 확인할 수 있고
데이터 엔지니어가 작업 파이프라인을 손쉽게 조율하고 통제할 수 있는 환경을 제공한다고 했다.

Dataverse, Amazon S3, Azure Databricks, Azure 등 이기종간 데이터 소스들이 하나의 인터페이스에서 통합되고 있어
다양한 데이터 소스를 Fabric을 통해 통합되어 실시간 탐색 가능하고
데이터 레이크하우스에 저장된 데이터는 분석 및 Power BI 에서도 즉시 활용 가능
Fabric의 데이터 연결성과 실시간 분석 기반 구성이 얼마나 직관적인지를 잘 보여주는 장표였다고 생각한다.
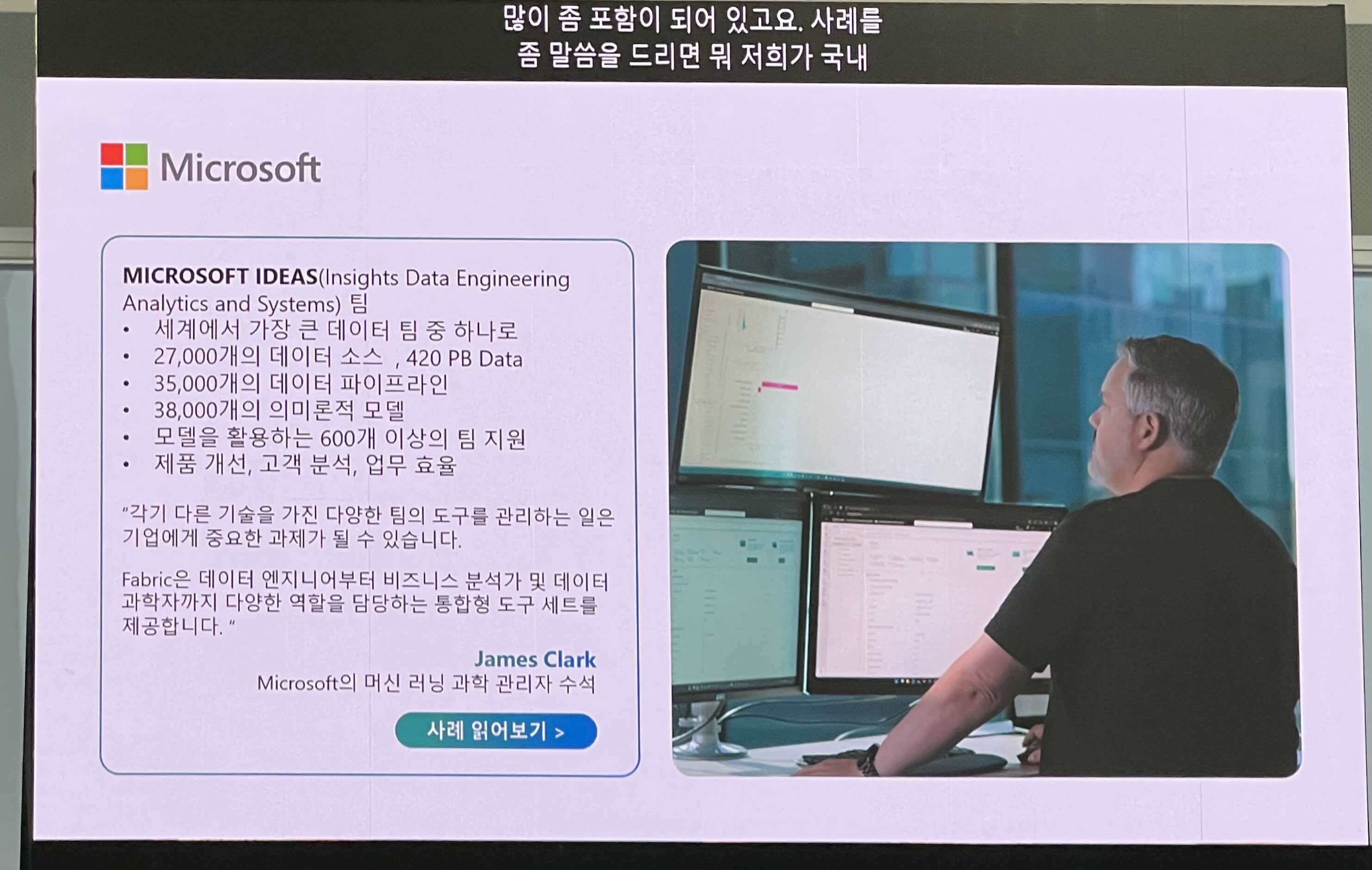
MS의 데이터팀(IDEAS)은 Fabric을 활용해 420PB 데이터, 35,000개 파이프라인, 38,000개 모델을 운영 중.
"MS도 실전에서 이걸 씁니다"라는 정도의 의미.. 다만 우리 회사에 바로 적용하긴 스케일 차이 큼. 참고용
유사한 구조의 반복이지만, 이번 슬라이드는 비즈니스 유저에게 친숙한 사용성을 부각한 포인트

“어디서든 데이터 가져오기” – OneLake 기반 통합 아키텍처
다양한 소스의 데이터를 이동이나 복제 없이 그대로 사용할 수 있도록 설계된 구조.
Azure, AWS, Google, On-prem 등에서 바로 데이터를 끌어다 쓸 수 있는 Shortcut 기능이 핵심
OneLake가 중심 허브 역할을 하며, Spark와 T-SQL을 통한 서버리스 컴퓨팅 환경이 기본
- 데이터 파이프라인 구축 없이 분석 환경 연결
- 다양한 클라우드 소스를 동일한 방식으로 활용 가능
- 데이터 가상화(Virtualization)로 복제 없이 분석 가능
"이제는 데이터 이동이 아니라 연결이 핵심이다."

앞서 설명한 모든 유연하고 통합된 버전과 더불어
보안 측면에서도 굉장히 훌륭하다라는 내용에 대한 설명
이번 AI Tour에서 소개된 Microsoft Fabric은 단순한 제품 그 이상이었다.
생성형 AI의 시대, 데이터를 어떻게 준비하고 연결하며 통제할 것인가에 대한
마이크로소프트의 해답을 제시한 셈인데, 여기서 정말 중요한 건 ‘Fabric’이라는 브랜드가 아니라
지금 데이터 환경 전반에서 통합 플랫폼 + 거버넌스 + 실시간 처리 + AI 연계가
모두 ‘기본값’이 되어가고 있다는 점이다.
결국 중요한 건 트렌드를 읽고, 우리 환경에 어떤 조각부터 들여올 수 있을지를 판단하는 안목이고
Fabric이 말한 메시지들을 우리의 시스템 구조 안에서 어떤 방식으로 적용할 수 있을지,
그 고민을 시작하기에 이번 행사는 꽤 괜찮은 자극이었던 것 같다.
마무리 느낀 점 및 핵심 요약
- 생성형 AI는 결국 데이터가 생명
→ "좋은 AI는 좋은 데이터에서 나온다"는 말 - DataOps와 ML Ops는 점점 가까워진다
→ 데이터 수집, 변환, 저장, 학습, 서빙까지 플랫폼이 연결된 형태가 대세 - 분산된 데이터 자산을 연결하는 전략이 핵심
→ 여러 SaaS, 데이터 웨어하우스, 레이크, AI 파이프라인을 하나의 구조 안에서 다룰 수 있느냐가 경쟁력 - Microsoft Fabric은 하나의 사례일 뿐
→ Google, AWS, Snowflake, Databricks 등도 유사한 구조로 진화 중
우리는 이 흐름을 기술적 중립성을 가지고 판단해야 한다.